[review] Domain Adaprive Faster R-CNN for Object Detection in the Wild
들어가기 앞서
Paper URL : https://arxiv.org/pdf/1803.03243.pdf
Paper Info : Yuhua Chen, Wen Li, Chistos Sakaridis, Dengxin Dai, Luc Van Gool (CVPR 2018)
References
- http://jaejunyoo.blogspot.com/2017/01/domain-adversarial-training-of-neural.html : DANN 에 대하여 잘 설명해주신 사이트입니다.
- http://theonly1.tistory.com/301 : 마찬가지로 Domain adaptation 에 대하여 잘 설명해주신 사이트입니다.
- https://arxiv.org/abs/1505.07818 : Domain-adverarial training of neural networks 논문입니다.
Abstract (원문 번역)
Object detection은 일반적으로 training과 test data들이 identical distributed한 환경에서 뽑혔다고 가정하는데, 이는 실제로는 항상 가능한 일은 아니다. 그러한 distribution 불일치는 상당항 성능저하를 유발한다. 본 연구에서 우리는, object detection의 cross-domain robustness를 향상시키는것을 목적으로 한다. 우리는 domain shift를 두 수준으로 다룬다:
- the image-level shift : 이미지 스타일, illumination(광학요소), 등등
- the instance-level shift : 물체의 외양, 크기 등등
우리는 최근의 state-of-the-art 모델인 Faster R-CNN 을 기반으로 연구를 진행하였으며, domain discrepancy를 줄이기 위하여 image level과 instance level에서의 두가지로 domain adaptation component들을 설계하였다. 두 domain adaptation component들은 이론에 기반하며, adversarial training 방식으로 domain classifier를 학습시키는것으로 구현되었다. 다른 level의 Domain classifier들은 consistency regularization에 의하여 더 강하게 Faster R-CNN의 region proposal network(RPN)을 학습하도록 강제될 수 있다. 우리는 우리가 제안한 새로운 접근법을 Cityscapes, KITTI, SIM10K, 등을 포함한 여러가지 데이터셋들을 사용하여 평가하였다. 결과는 우리가 제안한 기법이 다양한 domain shift 시나리오에도 강경하게 object detection을 수행할 수 있음을 보여주었다.
1.Introduction
Object Detection은 CNN의 발전에 힘입어 상당한 성능향상을 보여왔습니다. 하지만 여전히 training과 test데이터셋 사이에 상당항 domain shift를 일으킬수있는 view-points, object appearance, backgrounds, illumination, image quality, 등등 에서의 큰 변화에도 강경할 수 있는지는 도전적인 문제로 남아있습니다. 논문에서 사용한 예시와 같이 자율주행 차량의 경우를 생각해본다면, 학습할때 사용했던 이미지를 찍었을때의 카메라 상태와 주변 환경(날씨 등)은 실제로 주행할때의 상태와는 다를것입니다. 이러한 경우 ‘domain shift’가 발생하며 detection 성능을 저하 시킬 것입니다. Fig1을 통하여 실제로 각 데이터셋 별로 환경의 차이를 확인할 수 있습니다.

더 많고 다양한 환경을 가정하는 학습 데이터를 모으는것은 이러한 domain shift문제를 해결 할 수 있는 방법일 수 있지만 이는 굉자히 비용이 많이드는 작업입니다. 따라서 이러한 문제를 알고리즘수준으로 해결하기 위한것이 이 논문 및 domain adaptation분야의 핵심 목표입니다. 다시 정리하자면 Train set과 Test set간의 domain shift를 줄이는것이 목표입니다. 당연한 말이지만 이 논문에서 저자는 training 셋에 대하여는 지도학습을, target domain에 대하여는 지도학습이 불가능한(비지도학습을 하는) 시나리오에서의 domain adaptation을 고려하고 있습니다. 그렇기 때문에 어떠한 추가적인 annotation cost없이 문제를 완화할 수 있는 기법을 다루고자 하였습니다. 본 논문에서 저자는 기존의 Faster R-CNN object detection model을 기반으로 연구를 진행하였습니다. 따라서 이를 이해하기 위해서는 Faster R-CNN에 대하여 이해하는것이 좋습니다만 본 리뷰에서 다루지는 않을것입니다. 대신에 Faster R-CNN은 유명한 만큼 [link] 등의 많은 정리 글이 있으므로 이쪽을 추천드립니다!.
다시 돌아와서, 저자는 domain shift문제를 해결하기 위해서 두 domain (training, target) 간의 를 줄이는 방법을 사용하였습니다. 이때 domain clssifier와 detector를 adversarial 하게 학습시키는데, 여기 까지는 https://arxiv.org/abs/1505.07818 이 논문과 같습니다. 본 논문의 핵심 contribution은
- 확률론적 측면에서 cross-domain object detection문제를 이론적으로 분석하였으며
- image 수준, instance 수준에서 domain discrepancy를 완화시킬수 있는 두 domain daptation component들을 설계한것
- consistency regulatization을 사용하여 RPN을 더욱 domain invariant하게 만드는 방법을 제시한것
- 이 모든 방법들을 Faster R-CNN에 통합하여 end-to-end 방식으로 학습시킬 수 있도록 설계한 것
입니다. 개인적으로는 4번이 가장 큰 기여가 아닐까 생각합니다.
2. Related Work
- Object Detection
- Domain Adaptation
- Domain Adaptation Beyond Clssification : doamin adatpation문제가 주로 classification에서 다루어지며 그 밖의 vision task에 대하여는 잘 안다루지고 있다는 이야기 입니다. 몇몇 연구들을 소개하고있습니다.
3. Preliminaries
3.1 Faster R-CNN
3.2 Distribution Alignment with H-divergence
에 관한 설명입니다. 이는 간단히 말해서 두 domain간의 divergence를 수치적으로 나타내기 위한 방법입니다. 여기서 domain이란 sample 이라고 생각하면 될것같습니다. 더 직관적으로 각 데이터셋을 의미한다고 생각할 수 있습니다. feature vector를
라고 표현한다면 source domain의 feature vector를
, target domain의 것을
으로 표현 할 수 있습니다. 그리고 여기에 추가로 x가
에 속하는지
에 속하는지를 판별하는 분류기
가 있고
로 표현합니다. 이제
는 아래와 같이 표현됩니다.
보면 h가 를 오인할 확률과
를 오인할 확률을 더한값을 1에서 빼고 2를 곱한것입니다. 이때 두 도메인 샘을에 대한 분류기 h들의 집합
에 속해있는 모든 h들에 대한 에러율 중 가장 작은 값만을 사용합니다. 여기서 나타나는 특징은
와
은 서로 반비례관계에 있다는것입니다.
일반적으로 deep neural network 기반의 모델에서의 feature vector $$$x$$$는 특정 레이어에서의 활성화함수 를 거쳐서 나온 값입니다. 따라서 결과적으로 우리의 목적은 두 도메인같의 distance
를 작게 만드는
를 얻는 것입니다. 이를 식으로 표현하면 다음과 같아집니다.
즉 에러의 합의 최소값을 가장 크게 하고 domain distance를 가장 작게하는 를 찾는것인데 이는 adversarial training 방식으로 풀수있는 식이 됩니다. 그리고 이를 위해 Ganin 과 Lempitsky가 Unsupervised domain adaptation by backpropagation (ICML 2015) 에서 개발한 gradient reverse layer (GRL)을 사용합니다. (제 이해에는 GRL은 결국 그 이후의 에서의 역전파가 그 이전으로 진행되지 않게 하는것 뿐이라고 생각하고있습니다. 실제 구현도 아마도..) 이에 대하여는 이 블로그에 잘 정리되어있습니다 (감사합니다!). 최종적인 전체 구조는 아래 그림과 같습니다. (a)까지는 기존의 Faster R-CNN의 구조와 동일하겨 그 뒤로 본 논문에서 소개된 adversarial domain adaptation 모듈들이 추가되어있습니다. 뒤에 한번더 정리하겠지만 최종적인 loss 함수는 기존의 loss와 instance-level , image-level loss와 여기에 추가적으로 consistency regularization을 더합 값을 사용합니다.(각 모듈별 가중치가 붙기는 합니다)
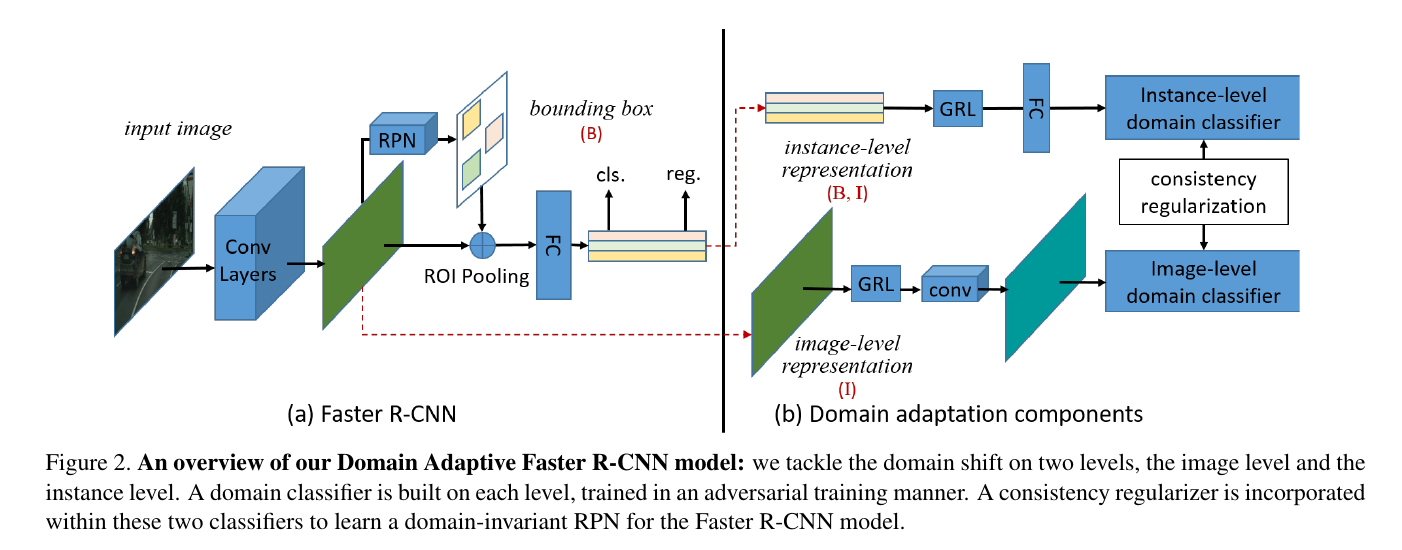
4. Domain Adaptation for Object Detection
4.1 A Probabilistic perspective
4.2 Domain Adaptation Components
4.2.1 Image-Level Adapation & Instance-Level Adaptation
이 절에서는 본격적으로 Image-Level Adaptation 과 Insnace-Level Apatation에 관하여 설명합니다. 간단히 정리하자면 image-level이라는건 roi로 뽑지않은 이미지 채로 어떤 sample 도메인에 속하는지를 분류하는것이라면 instance-level은 roi로 뽑은 영역들에 대하여 수행하는것입니다. domain discriminator 입장에서 보면 detection이 아니기 때문에 영역이 크게 중요하지는 않지요. 그러나 우리의 최종 목표가 domain invariant한 detector를 만드는것이기 때문에 이왕할거 instance-level도 고려하자 는것입니다. 그러나 이때 주목할 점은 본 논문에서 저자들은 image-level의 adaptation을 수행할 때 이미지 통채로 쓰지않고 patch 단위로 분류를 수행하였다는 점입니다. 이는 Fig.2의 (B)의 아래쪽 흐름의 새로운 conv 모듈을 통해 확인할 수 있습니다. 이를 통해 global한 변화에 덜 휩쓸리며 수행할때 input으로 사용되는 이미지의 resolution을 낮출 수 있기 때문에 한번에 여러개의 minibatch들을 사용할 수 있다는 것을 장점으로 언급하고 있습니다. 이 부분은 식으로 확인하는것이 더 간단할것같습니다. 우선 image-level domain adaptation loss입니다.
보시면 그냥 sample i들에 대한 도메인 분류기 h의 sigmoid cross entrophy loss 함수입니다. 는 해당 이미지가 어떤 도메인의 샘플인지에 대한 label이 됩니다. 무려 target domain은 detector를 학습시킬때는 지도학습 가능한 label이 없음에도불구하고 지금의 task에서는 어떤 도메인 출신인지 알수있기 때문에 이처럼 깔끔하게 학습 가능합니다. 또한 위에서 짚어본 바와 같이 image-level 에서는 patch단위로 학습을 수행하기 때문에 image i의 특정 좌표 u,v 별로(아마도 중심좌표) 수행하게 됩니다. 즉 이미지수 * patch 수 만큼 수행하게 됩니다.
여기서 한번더 adversarial 방식을 사용하였다는것의 의미를 짚어보자면, 원래 detector의 학습은 학습을 진행하면 할수록 training set인 source domain에 overfitting 되어갈 것이므로 결과적으로 위의 image-level domain adaptation loss를 maximize하는 방향으로 진행되게 됩니다. 반면에 위의 loss는 목적상 domain discriminator h가 구별하기 힘들도록 학습시키는 방향으로 학습을 진행하기 때문에, 즉 H-divergence가 감소하는 쪽으로 학습을 진행하기 때문에 base loss를 maximizaton 하는 방향으로 진행하는것과 같게됩니다. 이러한 adversarial training을 반복하면서 domain invariant하게 되어가게 될것입니다.
이를 이해하면 instance-leve adaptation loss도 마찬가지이기 때문에 간단해집니다.
instance-level에서는 이미지 i의 region proposal들 마다 수행하게 됩니다. 그것 외에는 image-level과 동일합니다.
여기까지의 loss들을 다 정리해보면 최종 loss 은
가 됩니다. ( 은 detector의 loss 입니다).
는 양측의 loss의 밸런스를 맞춰주기위한 상수입니다. 여기서 생각해볼만한 점은 image-level의 의 patch수와 instance-level의 proposal들의 수가 다른만큼 너무 차이나면 한쪽만 의미를 가질수도 있기에 여기도 보정을 해주는것이 좋지 않나 싶은데 딱히 그러지는 않은것 같습니다. 아마 수가 크게 차이나지는 않도록 해서이지 않을까 싶습니다.
4.2.2 Consistency Regularization
뒤의 실험을 통해서도 확인 할 수 있지만 사실 앞의 두 loss만으로도 충분히 좋은 효과가 얻어집니다. 하지만 저자분들께서는 여기서 한발짝 더 나아가 consistency regularization 까지 소개하였습니다. 이 부분은 제가 본 리뷰에서 건너뛴 부분인 4.1장에서 나타나는 부분인데, 결과만 요약하자면 image, instance 두 level의 domain classifier들 끼리도 distribution의 차이를 줄이는것으로 더 좋은 효과를 얻을 수 있다는것입니다. 이는 instance-level의 domain classifier 역시 image-level의 domain classification에 영향을 받기 때문입니다. 이 둘의 차이를 줄이기 위해서 본 논문에서는 간단하게 L2 regularigation을 사용하였고 여기에서 따서 consisteny regularization 이라고 이름 붙였습니다.
최종적으로는
이러한 loss 식이 얻어집니다.주목할 점은 이부분은 image의 수로 나눠주었다는 점입니다. 또한 각각에대하여 가중치를 붙이지 않고 하나의 가중치만 사용했다는점입니다. 딱히 신경쓰지 않은것인지 실험을 통해서 다르게 가중치를 둔것이 크게 효과가 없었는지는 잘 모르겠습니다.
5. Experiments
저자분들께서 서론에서도 언급하신 바와 같이 본 논문에서는 정말 다양한 실험을 통하여 논문에서 제시한 기법의 효용성을 실험적으로 입증하였습니다. 하지만 이 부분은 딱히 의아한 부분도 없고 논문을 참고하는것이 더 좋을것 같아서 따로 정리하지는 않겠습니다.
Author
Dohyeon Kim